

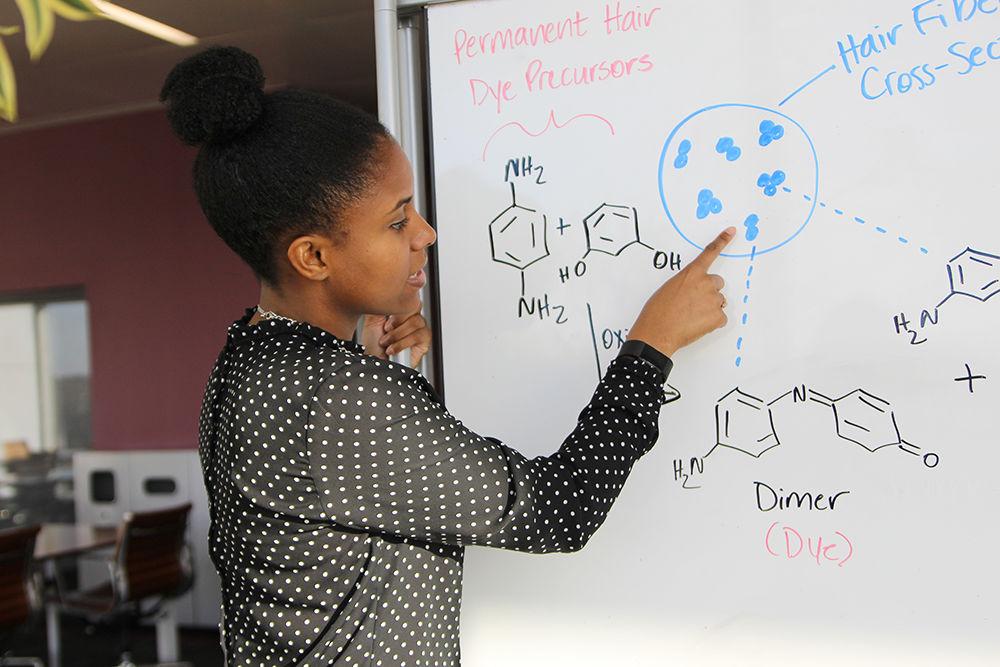
NC State researchers recently compiled the largest publicly available hair dye substance database. Through extensive research and analytical computation, their published study takes the first steps in identifying a more reliable process for designing and developing less toxic and more sustainable hair dyes.
The goal of this study served two key functions: developing a comprehensive database of hair dye substances and analyzing the database using computational methods.
Tova Williams, a fourth-year Ph.D. student studying fiber and polymer science, performed an extensive literature search for the relevant hair dye substance information.
“Traditionally, I’m a dye chemist,” Williams said. “I work with designing dyes and synthesizing them, as well as figuring out their properties. My research as a whole looks at approaches to the design of less toxic hair dyes.”
Reviewing the literature revealed the distinct classifications assigned to different hair dyes. According to Williams, the size and makeup of chemical structures serve as indicators of permanent, semi-permanent or temporary hair dyes.
The importance of distinguishing the sizes of hair dye chemical structures has to do with “fusion,” or whether the dyes properly get into the hair. Whereas temporary dyes rest on the outside of the hair, permanent and semi-permanent dyes are more interwoven within it. Permanent dyes additionally react and form larger molecular structures to resist easily washing out.
“As the names imply, they offer a certain degree of permanence,” Williams said. “We wanted to explore [these] relationships a little bit further and put some quantitative eyes on them. What I found was a lot of the temporary dyes are often recognized as semi-permanent dyes. This exposed the theory that one is larger than the other.”
By “quantitative eyes,” Williams is referring to the computational analytics performed by the cheminformatics division of the chemistry department. George Van Den Driessche, a third-year Ph.D. student studying chemistry, contributed to the analytical aspect of this study.
“Cheminformatics is a division of computational chemistry,” Van Den Driessche said. “We use molecular mechanics, some Newtonian laws and statistical models. The statistical models that we use specifically for machine learning or even clustering algorithms are a lot of the same models that are being used by insurance companies [or] Netflix, my favorite example.”
Van Den Driessche described these models as mechanisms akin to what companies like Netflix use to predict and identify the content that is most likely preferable to each individual customer. In a similar fashion, cheminformatics uses various computational techniques to sort and predict substance properties and behaviors.
“We’re taking those same algorithms and we’ve re-applied them to drug discovery, or in this case hair dyes,” Van Den Driessche said. “That’s a general overview of what cheminformatics is: data analysis of chemical systems and making predictions from that data for experimental chemists to test.”
Van Den Driessche primarily focused on categorizing the different dyes based on factors such as molecular weight and favorable compound interactions. The quantified and calculated averages of the dye type data revealed common and shared properties along these categorical parameters.
Van Den Driessche then used a technique known as “hierarchical clustering,” which involves breaking down and separating the data categories and values into increasingly narrowly-defined groups or “clusters” of similarity or specificity.
“What was interesting from this study is that using the chemical properties we were able to identify different regions that correlated to being permanent dyes, temporary dyes or semi-permanent dyes,” Van Den Driessche said.
Van Den Driessche described how we can infer from the clustering of information on chemical structures and properties, such as identifying a semi-permanent hair dye group found in red hair dye that can be referenced to design a new red hair dye. Clustering can also help identify the “chemical scaffolding” of dyes associated with bad skin sensitivity which allows designers to avoid composition in the future.
“The true beneficial thing about this is that with these computer models, we can do something that experimentally would take several years to complete,” Van Den Driessche said. “What our cheminformatics analysis enables us to do is go through 300 dyes, group them based on similar properties and say ‘we think these dyes can be very interesting for future testing,’ and now you’ve gone [down] from testing 300 to testing five.”
Williams also noted inconsistent groupings of different hair dye types. The expectation was that through this analysis, dyes that shared properties and permanence would form separate categories from each other.
“We saw many exceptions,” Williams said. “We were interested in the exceptions in the permanent hair dye precursors because we’re trying to design a permanent hair dye that’s less toxic.”
According to Williams, the next step currently involves utilizing the database and the analytical results to look at potential hair dye candidates among available substance catalogues. This includes NC State’s own Max A. Weaver Dye Library, which houses thousands of dye samples donated by the Eastman Chemical Company and potentially numerous sustainable hair dye designs.

George Van Den Driessche, a third-year chemistry Ph.D. student, works in a cheminformatics lab where he combines computational chemistry and statistical techniques to make decisions about chemical data. "My primary role with the hair dye substance database was to perform a lot of the cheminformatics analysis that we did." Van den Driessche said, "From there I assisted with the clustering analysis," which categorizes different dyes, and helps the researchers recognize trends in some of the properties of various dyes.





